How Sherpa built itself: one initiative, proposal to production
Sherpa governs its own development. Every feature in the framework went through the same lifecycle the framework enforces on everyone else: a proposal, a review, a plan, dispatched work, and an integration step that closes the loop. Nothing ships without a decision trail.
This is one of those trails, start to finish. The initiative is the Dispatch Center — the execution layer that turns "run this task on an AI agent" into something visible and governed. I picked it because it's a clean arc with a concrete result, and because it's the system that later ran most of Sherpa's other work. It built the thing that built the rest.
Here is the whole lifecycle as Studio shows it — research → proposal → plan → active → integrated, with the actual files attached:
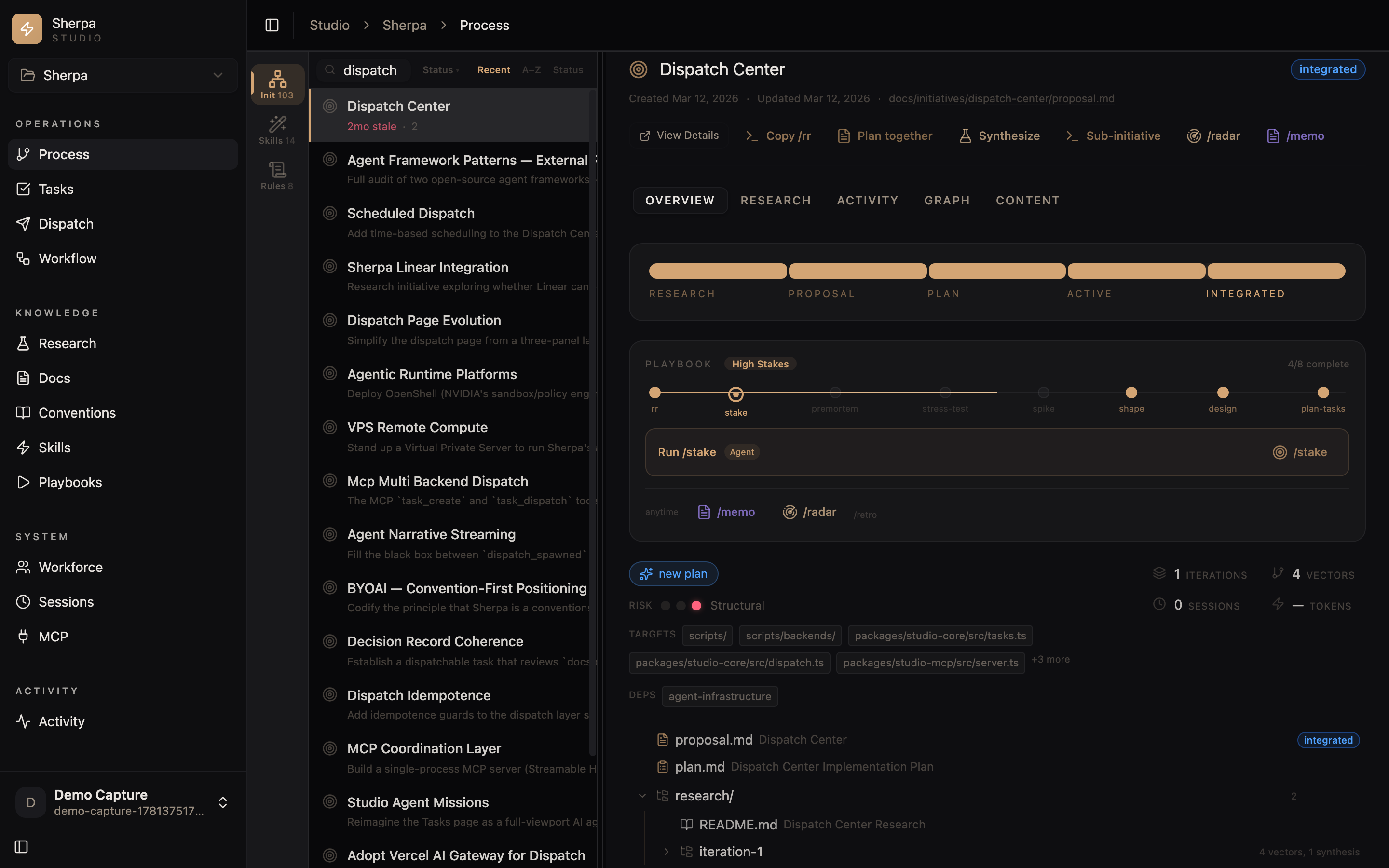
Stage 1 — The proposal: name the gap
The proposal (docs/initiatives/dispatch-center/proposal.md, created 2026-03-13) opens with a State Snapshot — what was true before any code:
Sherpa has the data model but not the execution layer.
studio-coreexposesgetTaskBoard(),getTaskDetail(), andgetTaskStats(). The MCP server hastask_list,task_get,task_create,task_update… What's missing: the 8 shell/Node scripts that actually dispatch tasks, manage workers, run judges, and orchestrate queues.
That's the discipline the proposal format forces: before proposing a change, write down what you believe the current state is, precisely enough that a reviewer can catch you if you're wrong. The gap here was specific — Sherpa could describe a task but couldn't run one, and it only understood two execution backends (Claude Code and LM Studio). The proposed change was equally specific: port the dispatch scripts and expand from 2 backends to 5, with task-type routing and a Studio UI where workforce capacity meets the backlog.
Stage 2 — Research: check the assumptions before committing
A proposal that depends on unverified assumptions is a guess. So the initiative ran a research cycle first, and the activity log records what it found:
Research iteration 1 — confirmed CLI flags for OpenCode (
run), Codex (exec), Gemini (-p). All 4 backends are scriptable. Free model benchmarks show MiniMax M2.5 best for instruction-following, Nemotron for long-context, MiMo for reasoning. Updated routing recommendation.
This is the step most "let's just build it" plans skip. The core assumption — "these CLIs can all be driven headlessly" — was the thing that would sink the whole effort if it were false. Confirming it took one research cycle and turned the routing design from a guess into a decision. (That same MiniMax benchmark later became a dispatched mission in its own right — the framework researching its own routing.)
Stage 3 — The plan: five sessions, explicit tasks
With the gap named and the assumptions checked, the work was broken into a five-session plan (plan.md), each session with concrete tasks and acceptance criteria. Effort in Sherpa is measured in sessions — one full working context — not calendar days, because the developer is an AI agent with variable session lengths. The plan sequenced the build so each session left the system in a working state:
- Session 1 — the script foundation (task scanner, board CLI, dispatcher, worker) plus the Claude backend.
- Session 2 — the four remaining backends: OpenCode, Codex, Gemini, LM Studio.
- Session 3 — TypeScript types, config integration, task-type routing, role frontmatter.
- Session 4 — the Dispatch Center UI: an 870-line three-panel component and its API route.
- Session 5 — auto-dispatch matching, docs, and the move to
integrated.
Stage 4 — Dispatched work: the build, recorded
The build ran across those five sessions. The activity log's own accounting:
Implementation complete in 5 sessions… Total: 52 files changed, ~6,500 lines added.
And then the moment that proved the whole thing worked — the first task dispatched from the browser to a non-Claude backend:
First successful browser→Gemini dispatch: "Benchmark Gemini vs MiniMax on content generation tasks" completed in 41 minutes.
That mission, and the ~100 that followed it, land on the task board the Dispatch Center shipped — the same board, filterable by all the backends this initiative added:
One detail from the polish pass is worth pulling out, because it's a governance decision encoded in code: a Claude-only constraint for governance files. Any task touching CLAUDE.md, .claude/, or agent role definitions is forced onto the Claude backend regardless of routing — those files steer every other agent, so they don't get edited by whichever model was cheapest that night. The initiative didn't just add backends; it added a rule about when not to use them.
Stage 5 — Integration: close the loop, plant the seeds
When the work was done, the initiative moved to integrated and did the thing the lifecycle requires at the end: it wrote down what it deliberately didn't do. The Seeds section lists follow-on work that surfaced during the build and was scoped out on purpose — each one a candidate for its own future initiative:
- MCP HTTP Streamable transport — the MCP server was stdio-only; Studio web couldn't call it directly. → became the
mcp-coordination-layerinitiative. - Scheduled dispatch — time-based queuing and recurring tasks. → became the
scheduled-dispatchinitiative. - Cost tracking dashboard — per-backend spend visibility, which at the time lived "in config and in Rob's head."
That last line is the honest kind of note the format is for. And the first two seeds are real bidirectional links: the completed initiative points forward to its children, and each child points back via spawned-from. The trail doesn't end — it branches.
Why this matters
A hiring manager's hardest question about a solo project is "did they design a system, or wire together libraries?" This is the answer in one artifact. The Dispatch Center wasn't built by opening an editor and typing. It was proposed against a stated baseline, de-risked with a research cycle, planned into sessions, built in tracked steps, and closed with an honest account of what was left for later — all of it recorded by the same governance system the framework sells.
The framework didn't just get built. It got built the way it tells you to build, and kept the receipts.